kilo from the ground up, and have made it
about halfway through “Chapter 4” which is the first chapter to really pick up
the pace with the “text editor” bits. Up to this point (Chapters 1-3), we’ve
been concerned with laying down the groundwork for building a UI using VT100
commands and doing tasks like moving the cursor around the screen and handling
interacting with the terminal device in a clean fashion. Chapter 4 concerns
itself with making a text viewer and really brings out the quirks in human
language as we start to dive into handling displaying text and moving a cursor
around it in a meaningful way.
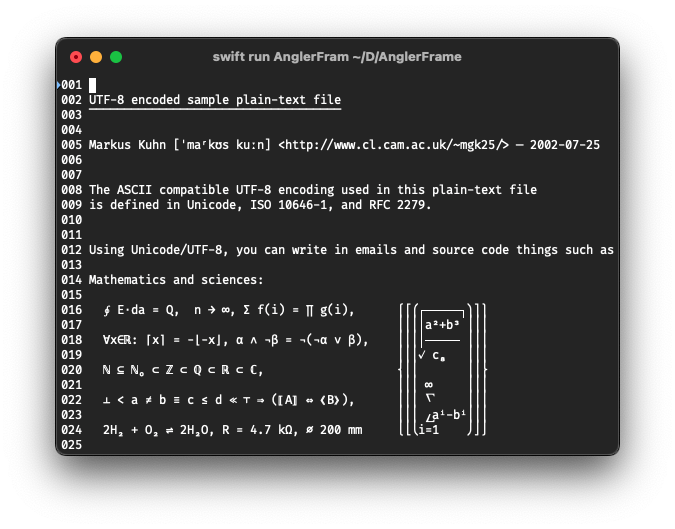
At this point I’ve already implemented a few features that take a departure
from the standard kilo, as well as having a fairly different take on the code
layout. I’ve gotten UTF-8 displaying without issue thanks to Swift (although
I’m sure I’ve got a few length bugs and other issues that’ll surface as I work
on “Chapter 5” which implements text-editing) and I’ve made the cursor behave
more similar to Vim (more on this below) and I’ve got line numbers in a
“gutter.”
In terms of code changes, I’ve made use of structs and classes in Swift to
organize and further abstract some of the code away. At the moment, I’ve got an
Editor class which is the heart of the system, integrating with a Display
object which concerns itself with outputting things, and an Input object
which concerns itself with converting raw input from FileHandle.read(_:) into
a nicer enum. This should make it a little nicer to work on future expansions,
such as: convert the Input code into an async system, where it’d write into a
buffer that can be read from the main thread. It also feels a lot more “Swifty”
to me and gets around some of the ugliness of C and its lack of name spacing
and methods.
Cursor Movement
The situation: You’re moving vertically from a longer line to a shorter line, and the cursor is positioned in a column past the end of the shorter lines length.
Take, for example, the following lines:
- line 1: 5 columns
- line 2: 2 columns
- line 3: 10 columns
What happens to the cursor if you have it at column 4 on line 1, and move it to line 2? What happens when it moves from line 2 to line 3 after this?
In the original kilo, the cursor sets its position to the shorter lines
length, effectively snapping it to a new position. In the above example, this
moves the cursor from column 4 to column 2, and when you subsequently move from
line 2 to line 3, the cursor remains in the new position of column 2. This is a
little annoying because if you are trying to compare column positions and
encounter a blank line, the cursor loses all context of where it originally
was!
In Vim, however, the cursor is displayed as snapping to the end of the shorter line but it retains its original column position when navigating. This means that in our example above, the cursor appears to snap back to column 2 on line 2, but will return to column 4 on line 3, keeping continuity a little better. When you insert text where the cursor is displayed at a different column from its remembered position, it resets to the currently displayed position. So if you move from column 4 on line 1 to line 2 and then insert a character, the new cursor’s position will be column 3 after the insert, because it reset to column 2 on the insert and then moved over one column for the inserted character.
I’ve copied this behavior from Vim as I find it a lot more intuitive to how the cursor should move around text and even make use of the feature to find in correct indents, for example. It turned out to be fairly easy, using Swift’s computed properties:
// The Cursor is in "file space," not "screen space" which means that it
// actually represents where at in the file the cursor is, and requires
// translation via adding the scrollOffsets and any gutters/UI paddings
// before it can be displayed correctly.
var cursor: (col: Int, row: Int) = (0, 0)
// It's possible that the current row is shorter than the row we just came
// from, and that our cursor might be in the middle of nowhere. To match
// Vim's behavior where it'll keep the original column as you move around,
// visually snapping the cursor to the end of the line, we use this second
// "displayedCursor" which snaps the cursor but doesn't change the cursors
// original column. If you then insert while on a column that is different
// from the current cursor, we'll update the cursor to the current column.
var displayedCursor: (col: Int, row: Int) {
guard let currentRow
else { return cursor }
let minCol = min(currentRow.count, cursor.col)
return (minCol, cursor.row)
}
Now, when moving the cursor with the escape sequence: ^[<row>;<col>H, I just
have to pass in the displayedCursor values instead to get this visual
snapping while remembering the original column. And when navigating left/right,
and when I get to inserting text in the next chapter, I just have a small check
to reset the cursor’s real position to the displayed position if the two don’t
match.
String Indexing
One of the big “pain points” that I’ve hit so far is dealing with differences
in string handling. In kilo, both because it’s concerned with just ASCII text
where a character fits into a single byte, and because C-strings are just
simple arrays, it gets away with using direct indexing into the string and
directly manipulating a length integer when it needs a slice. This plays nicely
with tracking the column width and scroll offsets in integers as well, since
you can start indexing from the scroll offset directly, up to the column width
or string length.
So, for example, to pick out the text that is visible during a horizontal scroll,
kilo does something similar to:
int len = E.row[filerow].rsize - E.coloff;
if (len < 0) len = 0;
if (len > E.screencols) len = E.screencols;
abAppend(ab, &E.row[filerow].render[E.coloff], len);
Where E.coloff is the horizontal scroll offset, E.screencols is the screens
width in columns, with E.row[filerow].render being the character array/string
for a single line and finally rsize being the number of characters in the
current line.
This code is fairly short and succinct but it doesn’t translate one-to-one in Swift. One initial thought, you might think we could write something similar to:
var len = max(0, editor.rows[filerow].count)
len = min(len, editor.screenSize.cols)
display.buffer(string: editor.rows[filerow][editior.scrollOffset.col..<len])
But we quickly run into an error:
error: 'subscript(_:)' is unavailable: cannot subscript String with an integer range, use a String.Index range instead.
Swift explicitly tells us that it needs us to use String.Index instead of
integers, but why?. A big reason is because internally Swift represents strings
differently from C, allowing it to better handle things like Unicode. In
Unicode, such as the UTF-8 version, a single character visually might be
composed of a number of bytes (a “grapheme cluster”) rather than just one. By
using String.Index, Swift can correctly calculate things like “the next
character” without cutting a grapheme cluster in half. So how do we use it?
Well, thankfully Swift gives us a few helpers, such as the String.startIndex and
String.endIndex properties as well as String.index(_:offsetBy:). Using
these, we can slice our line in the same fashion that kilo does, all while
being (more) aware of UTF-8 and friends:
let row = rows[fileRow]
let startOffset = scrollOffset.col
let endOffset = lineLength + scrollOffset.col
if let startIndex = row.index(row.startIndex, offsetBy: startOffset, limitedBy: row.endIndex) {
let endIndex = row.index(startIndex, offsetBy: endOffset, limitedBy: row.endIndex) ?? row.endIndex
let displayedRow = row[startIndex..<endIndex]
display.buffer(string: String(displayedRow))
}
Here, we can calculate the offsets the same way, just using some simple integer
math, but we have to convert them into indexes. We also use limitedBy: to
ensure that we’re not going to throw an out-of-bounds error if we’re trying to
access an offset that is bigger than the current lines length. This approach
also forces us to consider common failure cases such as a line that is shorter
than the screen, or a line that has been completely scrolled off the screen.
Every time I run into this, it feels a bit frustrating to write at the time. It’s something that feels like a case that the language should smooth over for the developer and it’s a lot more verbose than the same code in a lot of other languages. However, it’s not all bad: the design of this system forces the developer to move past the outdated fashion of thinking of text as a simple array of bytes and towards the thought that it’s a more complex system that handles a number of quirks and oddities that come from the complexities of human writing.
Anyways, hopefully this has been a fun little adventure into two of the many little adventures I’ve had while working on this fun side project!
]]>